2021. 4. 8. 15:56ㆍData Analysis/Deep Learning

안녕하세요.
데이터 분석하는 새내기 대학원생, 석사 1학기 고니입니다.
이번 게시글을 시작으로 딥러닝에 대한 이야기를 함께 나누어보려고 합니다. 그 이름도 유명한 딥러닝이 도대체 무엇인지부터 시작하여 딥러닝의 발전 역사를 지나, 현재 사용되고 있는 다양한 형태의 딥러닝 기법 소개까지 딥러닝에 대한 전반적인 이야기를 다룰 예정입니다.
딥러닝이라는 단어는 누구나 한 번쯤 들어보셨을 것입니다. 여러분께서도 어디선가 딥러닝이라는 단어를 접하셨기 때문에 지금 이 글을 읽고 계실 것입니다. 도대체 딥러닝이 무엇이길래 전세계가 이토록 열광하는 것일까요? 첫 시간에는 바로 이 딥러닝이 무엇인지에 대한 이야기를 나누어보려고 합니다.

딥러닝(Deep Learning)을 한 문장으로 표현하면 다음과 같습니다.
"여러 층을 가진 인공신경망(Artificial Neural Network, ANN)을 사용하여
기계를 학습시키는 일종의 머신러닝"
위 문장에서 우리는 크게 두 부분에 집중해야 합니다.
- 여러 층을 가진 인공신경망
- 일종의 머신러닝
# 여러 층을 가진 인공신경망
딥러닝에서 가장 기본이 되는 개념이 바로 인공신경망(Artificial Neural Network, ANN)입니다. 인공신경망에 대한 자세한 이야기는 다음 게시글인 “대학원생이 알려주는 친절한 딥러닝 기초 (2) - 인공신경망의 출발”부터 본격적으로 다루기 시작하겠습니다.
그래도 도대체 왜 우리가 딥러닝을 이해하는데 있어서 “여러 층을 가진 인공신경망”에 주목해야 하는지는 이번 글에서 말씀을 드려야하므로 인공신경망이 어떻게 생긴 것인지에 그 구조에 대해서만 간단히 소개해드리는 시간을 가지려고 합니다.
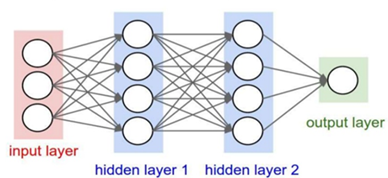
인공신경망은 위의 그림과 같이 학습하고자 하는 데이터를 입력받는 입력층(Input Layer), 결과를 출력하는 출력층(Output Layer), 그리고 그 사이에 위치한 은닉층(Hidden Layer)으로 구성되어 있습니다.
“입력층에서 데이터를 받고, 출력층에서 결과를 내보내는구나!"
...
"그런데 도대체 은닉층은 뭐지?”
라는 의문이 드시는 분들이 많으실 것입니다.
초기의 인공신경망은 입력층과 출력층으로만 구성된 아주 간단한 형태였습니다. 그러나 입력층과 출력층만이 존재했을 때 해결할 수 없는 한계점이 발생했고, 이를 해결하기 위해 입력층과 출력층 사이에 은닉층이 탄생했습니다. 입력층과 출력층만이 존재했을 때 과연 어떠한 한계점이 있었는지, 은닉층이 그 한계점을 어떻게 해결했는지에 대한 이야기는 추후의 게시글에 다룰 예정입니다.
이 은닉층은 인공신경망 내부에 1개의 층만 존재할 수도 있고 2개 이상의 층이 존재할 수도 있습니다. 물론 초기의 인공신경망에서처럼 아예 은닉층이 존재하지 않을 수도 있습니다. 인공신경망은 은닉층의 개수에 따라 다음과 같이 분류될 수 있습니다.

위 표에서 심층신경망 즉, 2개 이상의 은닉층으로 구성된 인공신경망을 깊은 신경망(Deep Neural Network, DNN)이라고 부르며, 이를 활용한 머신러닝 학습이 바로 그 유명한 딥러닝입니다.
# 일종의 머신러닝
앞선 문장에서, 2개 이상의 은닉층으로 구성된 인공신경망을 활용한 머신러닝 학습이 바로 딥러닝이라고 말씀드렸습니다. 즉, 딥러닝은 전혀 다른 세상의 새로운 이야기인 것이 아니라 일종의 머신러닝입니다.
물론 딥러닝이 머신러닝의 일부이지만, 그럼에도 딥러닝과 일반적인 머신러닝 사이에는 몇 가지 차이점이 존재합니다.
1. Feature Extraction
일반적인 머신러닝에서는 데이터의 특징 즉, 모델이 학습에 필요로 하는 변수들을 사람이 추출하여 기계에게 입력해줍니다. 반면, 딥러닝은 기계가 직접 데이터로부터 결과 도출을 위한 의사결정을 내리고 필요한 특징을 추출합니다. 즉, 머신러닝에서 사람이 해주어야 했던 과정을 딥러닝에서는 기계가 직접합니다.

위의 그림에서 머신러닝은 사람이 데이터의 특징을 추출하는(Manual Feature Extraction) 과정을 통해 머신러닝 모델에 정보를 넣어주는 모습을 살펴볼 수 있습니다.
반면, 아래의 딥러닝에서는 그러한 과정이 없습니다.
2. 데이터 의존도(Data Dependencies)
전세계가 열광하고 있는 딥러닝이지만 항상 최고의 성능을 자랑하는 것은 아닙니다. 딥러닝 알고리즘이 올바르게 임무를 수행을 하기 위해서는 많은 양의 데이터가 필요합니다. 다시 말해, 데이터가 충분하지 못하다면 딥러닝 알고리즘은 힘을 쓰지 못한다는 것입니다. 이런 경우, 일반적인 머신러닝 기법이 더욱 좋은 성능을 자랑하고는 합니다.

3. 하드웨어 의존도(Hardware Dependencies)
일반적인 머신러닝은 저사양의 컴퓨터에서도 실행할 수 있지만, 딥러닝은 그래픽 처리 장치(Graphic Processing Unit, GPU)가 포함된 고사양의 하드웨어를 필요로 합니다.
4. 학습 시간(Training Time)
일반적인 머신러닝은 짧게는 수 초에서 통상 길어도 수 시간 정도면 학습이 가능합니다. 반면, 딥러닝은 길게는 몇 주까지 오랜 시간의 학습 시간이 걸립니다.
5. 결과 해석(Result Interpretability)
일반적인 머신러닝 알고리즘은 결과에 대한 해석이 가능합니다. 어떠한 이유로 이러한 결과가 출력되었는지에 대한 해석을 할 수 있다는 의미입니다. 그러나 안타깝게도 딥러닝의 결과는 사람이 해석할 수 없습니다. 얼마나 좋은 성능을 가졌는지는 알 수 있으나 그 좋은 성능을 가진 모델이 왜 이러한 결과를 도출해 냈는지에 대해서는 알 수 없습니다.
딥러닝 관련 첫 포스팅인데 이해가 잘 되셨을지 모르겠습니다. 제 글에 대해 추가로 궁금하신 점이나 지적해주실 부분이 있으시다면 언제든지 댓글 부탁드립니다!
다음 시간에는 딥러닝의 기본이 되는 인공신경망의 출발에 대한 이야기를 나눠보려고 합니다.
'Data Analysis > Deep Learning' 카테고리의 다른 글
| 대학원생이 알려주는 친절한 딥러닝 (5) - 활성화 함수 (4) | 2022.01.12 |
|---|---|
| 대학원생이 알려주는 친절한 딥러닝 (4) - 다층 퍼셉트론 (0) | 2021.05.11 |
| 대학원생이 알려주는 친절한 딥러닝 (3) - 퍼셉트론의 등장과 인공지능의 1차 겨울 (3) | 2021.04.18 |
| 대학원생이 알려주는 친절한 딥러닝 (2) - 인공신경망의 출발 (0) | 2021.04.09 |